2022 Annual Meeting
(148e) Design of the Cooling Crystallization Process Using the Machine Learning-Based Strategy
Author
At present, the approach adopted by researchers and industry is to predict product quality through modeling. That is, relying on the PAT tool, the relationship between concentration changes over time should be obtained through experiments, and parameters in the nucleation and growth kinetic model can be obtained by combining PSD changes before and after. Validation experiments are needed to evaluate the reliability of the obtained kinetic model. Furthermore, the PSD and process yield under unknown crystallization conditions can be obtained by solving the population balance equation (PBE) and mass balance (MB) including the kinetic models. For some systems, the contribution of particle agglomeration or breakage to the PSD should be considered as well. Although the modeling approach as mentioned earlier has been widely used in crystallization process design and process control, it still has some application limitations. First, the quantitative relationship between particle size and concentration over time in the solution system during crystallization, which is necessary for nucleation and growth kinetic models, needs to be obtained using the process analytical technology (PAT) tools. However, PAT tools, such as Raman spectroscopy, attenuated total reflectance Fourier-transform infrared(ATR-FTIR), ultravioletâvisible(UV-Vis), and focused beam reflectance measurement (FBRM), are pretty expensive. Also, these PAT tools have a lower limit of detection for spectroscopic instruments, limiting the detection of insoluble compounds at low concentrations. Secondly, the currently widely used invasive probe may also lead to fouling on the surface of the probe, which makes the detection impossible. Secondly, the accurate determination of crystallization kinetic parameters requires professionals to design experiments to isolate the processes of primary nucleation, secondary nucleation, growth, particle agglomeration and breakage, which will reduce the degree of difficulty in multi-parameters optimization. In addition, for some compounds where an empirical formula is not available, such as the protein crystallization process with long induction periods, the nucleation kinetics cannot be accurately obtained using the traditional primary nucleation modeling. Therefore, the development of robust prediction methods to reduce costs and improve accuracy is the key to breaking through the limitations of current applications.
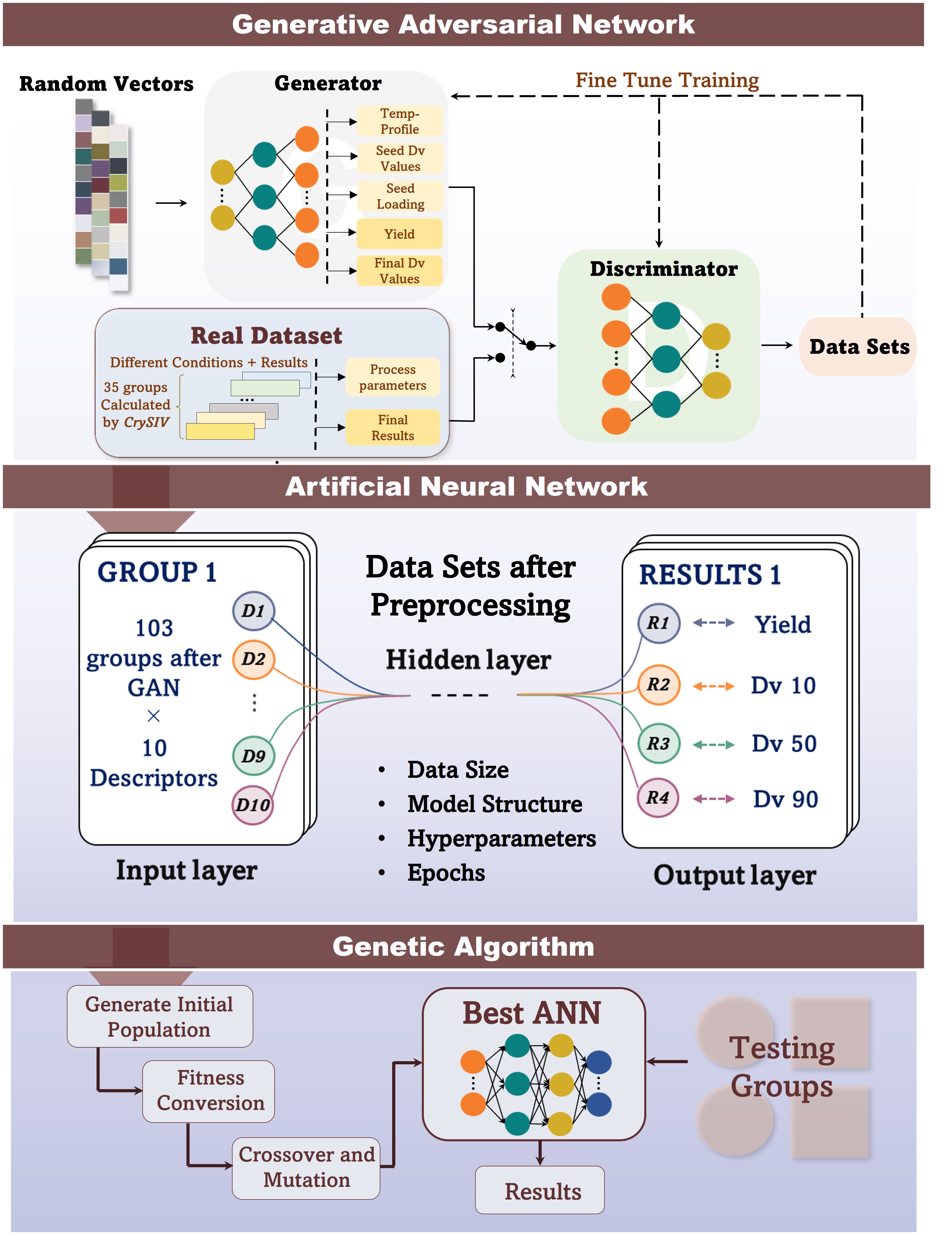
Machine learning (ML) is a data-based approach for problem solving and information mining. It relies on self-learning ability and can generate information automatically. As the most common supervised learning algorithm in ML models, Artificial neural network (ANN) has been widely used in engineering, especially in the field of crystallization. In recent years, we have continued to focus on the cross-discipline between crystallization and ML, and have tried to use the ANN algorithm to replace complex crystallization processes or predict the special properties of products and have already made some progress[1,2]. Therefore, we believe that the optimized ML models can be used to establish the quantitative relationship between process parameters and yield and PSD during the crystallization process. Obtaining a reliable dataset is the focus of constructing ML models. When literature data is not available, it is necessary to obtain a large number of training and testing set samples through high-throughput experiments. Although a certain number of experiments is necessary, it cannot be denied that if we conduct close to or more than a hundred sets of experiments as an initial dataset for ML models, it is contrary to our desire to develop alternative methods with the advantages of efficient, accurate and fast. It will also cause materials waste and labor costs. To expand the initial dataset, we propose the CrystGAN, a generative adversarial network (GAN)-based model that learns to generate new data including crystallization conditions and product results while ensuring high generation accuracy, which could be treated as an alternative way to large-scale crystallization experiments. It is also the first time use GAN in the industrial crystallization process.
In this work, ML models for PSD and yield prediction were built based on two algorithms, named GAN and ANN, to replace traditional time-consuming and complex crystallization kinetics-based modeling. The real dataset was achieved using CrySiV software (developed by Zoltan Nagy, Purdue University) simulation[3]. Each group in the dataset contains initial conditions (including particle size distribution represented in DV values, seed loading, compound concentration), temperature profile (including five values for different cooling rates from 60â to 10â), and results (including final PSD represented in DV values, yield).
In order to use as little real data as possible, 20-40 real data groups are adopted as the input of the CrystGAN model, and the generated accuracy in using different real data is compared. The generated data and the real data set are combined to train the ANN model. It can be found that after using more than 35 real data groups, the prediction ability of the CrystGAN-ANN model has not been significantly improved. Therefore, we can determine that the minimum number of real data used to accomplish the PSD and yield prediction of the cooling crystallization process is 35 groups. In addition, the genetic algorithm (GA) is used to optimize the hyperparameters of the ANN model further. Finally, the root mean square error (RMSE) of the optimal yield prediction value of the proposed CrystGAN-ANN-GA model is 4.49, and the accuracy of the DV values is not higher than 10.12, which means we have achieved our preset prediction purpose.
At present, there is increasing research on applying ML to study chemical engineering. We hope to provide guidance and reference through our work for the regression and prediction of complex multi-factor systems in relevant fields.
References
[1] Y.Ma, J. Gong, et al. (2021): Design of Spherical Crystallization of Active Pharmaceutical Ingredients via a Highly Efficient Strategy: From Screening to Preparation, ACS Sustainable Chemistry & Engineering 9, 27, 9018â9032.
[2] Y.Ma, J. Gong, et al. (2021): Machine learning-based solubility prediction and methodology evaluation of active pharmaceutical ingredients in industrial crystallization, Frontiers of Chemical Science and Engineering 16, pages523â535 (2022)
[3] B. Szilagyi, Z. Nagy, et al. (2021): Cross-Pharma Collaboration for the Development of a Simulation Tool for the Model-Based Digital Design of Pharmaceutical Crystallization Processes (CrySiV), Crystal Growth & Design 21, 6448â6464.