(314e) Web Application for LEAPS2 – a Surrogate Selection Framework
AIChE Annual Meeting
2023
2023 AIChE Annual Meeting
Topical Conference: Next-Gen Manufacturing
Industry 4.0, Digital Twins, and Digital Transformation
Monday, November 6, 2023 - 9:00am to 9:20am
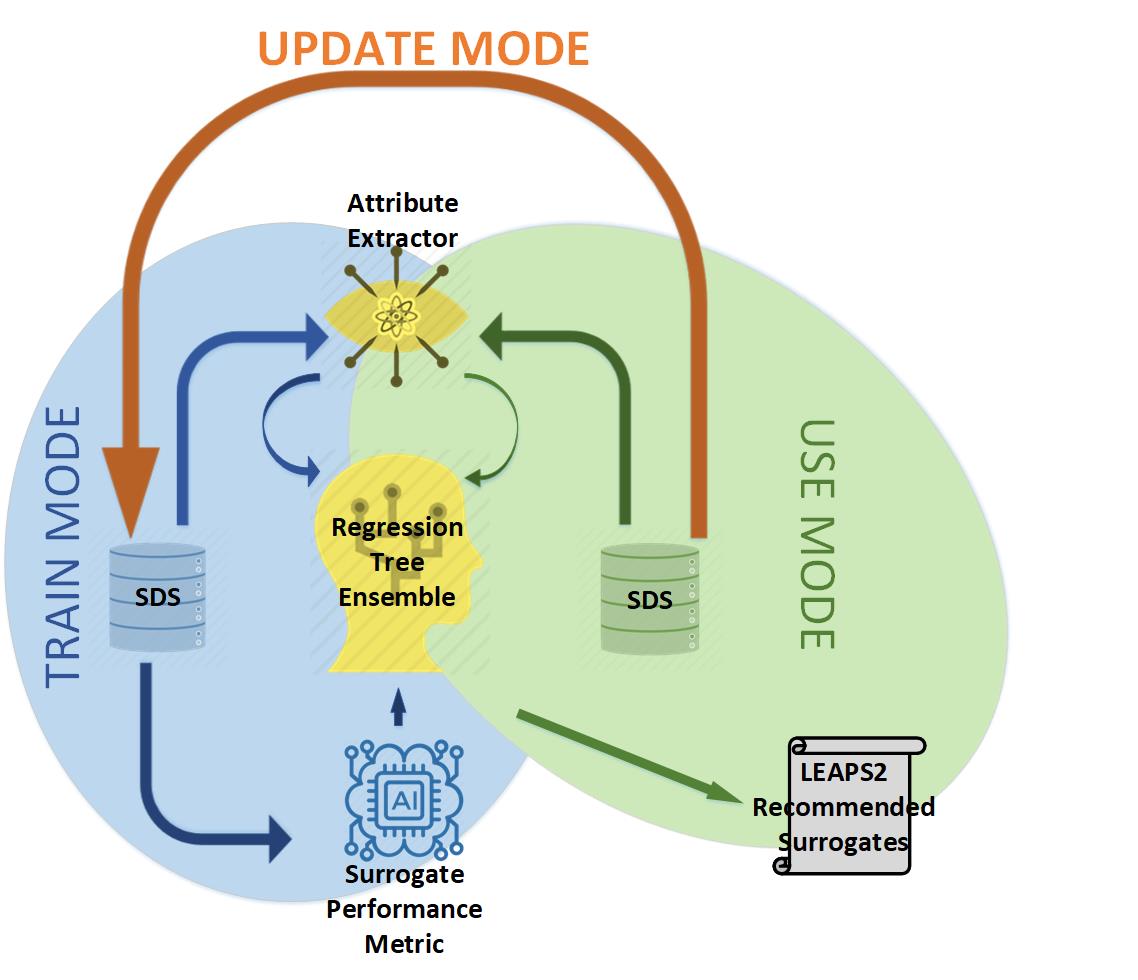
With this motivation, we developed a meta-learning-based surrogate selection framework, LEAPS2 (Learning based Evolutionary Assistive Paradigm for Surrogate Selection) (Ahmad and Karimi, 2021; Garud et al., 2018), to automate the surrogate selection process for any given data set. LEAPS2 operates in three modes – train mode, use mode, and update mode (see figure below). In the train mode, LEAPS2 learns surrogate performances over a large bank of non-noisy and noisy data sets by correlating the performances to certain data attributes. In the use mode, LEAPS2 uses its acquired knowledge to estimate surrogate performances for any given data set, and recommend a few best surrogates. In the update mode, LEAPS2 updates its knowledge by learning surrogate performances for new data sets, thereby progressively enhancing its knowledge with time.
We have developed a web-based application of LEAPS2 using Streamlit that can be accessed from https://leaps2.streamlit.app. As Streamlit is an open-source application framework, our tool can be used freely without the need of any third-party licensed software. The LEAPS2 framework within our tool has been trained on more than 5000 multi-dimensional (upto 20-dimensions) non-noisy and noisy data sets. Its surrogate pool comprises of 36 distinct surrogate forms from which a few surrogates are recommended. The tool comprises of three tabs – “Recommendâ€, “Evaluate / Useâ€, and “Helpâ€. The “Recommend†tab is the location where the user can receive surrogate recommendations for modeling a given data set. The data set is to be uploaded as a comma-separated values (csv) file in a specified format. In case of noisy data, our tool queries some optional inputs from the user to prevent recommendation of overfitting surrogates. It either uses a user-specified estimate of noise variance in the response data, or a threshold on minimum mean squared error or maximum R2 to avoid recommending surrogates that may potentially fit noise in the response data. In the absence of user response, our tool uses a limit of . Our tool also provides the user the flexibility to choose a desired surrogate performance metric based on which the surrogates should be recommended. The user can either select an error-based metric (mean squared error, mean absolute error, and coefficient of determination or R2) or a composite accuracy-cum-complexity metric (Surrogate Quality Score or SQS) (Ahmad and Karimi, 2021). Error-based metrics favor surrogates with low prediction error, while SQS combines model accuracy and complexity into a single score to favor simple and accurate surrogates. Each time a user uploads a data set in the “Recommend†tab, our tool seeks the user’s permission whether their data can be saved for updating LEAPS2 in the future. The “Evaluate / Use†tab of the tool allows the user to assess the prediction performance of the recommended surrogates by performing hold-out validation. The split fraction to divide the data set into train and test sets can be specified by the user. Moreover, in this tab, the user can download a copy of the trained surrogates as a pickle file. The pickle file can be imported in Python, and the trained model can be used for making future predictions at new data points. Additionally, our tool allows the user to directly upload a csv file comprising of the test points to obtain corresponding predictions from the trained surrogates, without the need to download the pickle file. Detailed instructions on key features of the tool, and its usage are included within the “Help†tab of the tool.
Thus far, we have used our tool for making surrogate recommendations for various real-world data sets. To validate the recommendation performance of our tool, we obtained its recommendations on all the data sets used to train LEAPS2. Our tool successfully recommended at least one of the three true best surrogates for more than 90% of the data sets, highlighting its ability to often recommend best surrogates. With timely improvements based on comments and feedback, we hope that our tool can serve as a valuable component for industrial digitalization.