

-

-
Topics:
Artificial intelligence (AI) and machine learning (ML) have become hot topics for chemical engineering and every other discipline. This article clarifies what AI/ML encompasses and speculates on how its impacts will be felt.
AIChE’s Public Affairs & Information Committee (PAIC) assembled an ad-hoc working group on AI/ML. The working group considered the context and use of AI/ML within present and future chemical engineering application domains.
The evolution of AI concepts
AI concepts began in the 1950s — notably during a 1956 Dartmouth conference — and were influenced by a 1950 paper by Alan Turing. ML is the most public-facing subdivision of AI because ML deals with the extraction of patterns, models, and knowledge from data. It arose with neural networks in the early 1980s and has evolved to take advantage of sophisticated learning algorithms, more powerful and easily accessible computers, and the generation of data with the characteristics of “big data.”
In fall of 2022, ChatGPT (Version 3.5) created a wave of enthusiasm by generating natural-language discussions based on a user’s text input. It uses generative large language models (LLMs) trained on very large amounts of text so that users can engage in a chat with the model.
How ChemEs can use ML and LLMs
The ways in which ML and LLMs can be deployed are numerous. For example, chemical engineers could use these tools to:
- postulate new frameworks for production
- aid report writing
- help to design safe processes and products that would be good for human health, better sustain the environment, and satisfy regulatory requirements
- speed up smart manufacturing beyond design of experiments
- aid code development, especially for those with limited programming background
- determine optimal nutrition profiles to help optimize yields and selectivity in bioprocesses.
- Some important dimensions of using AI/ML that must also be considered are ethics, responsible use, and scalability.
Machine-learning use case
The following use case for engineering chemical processes illustrates general AI/ML approaches, summarized by the following image:
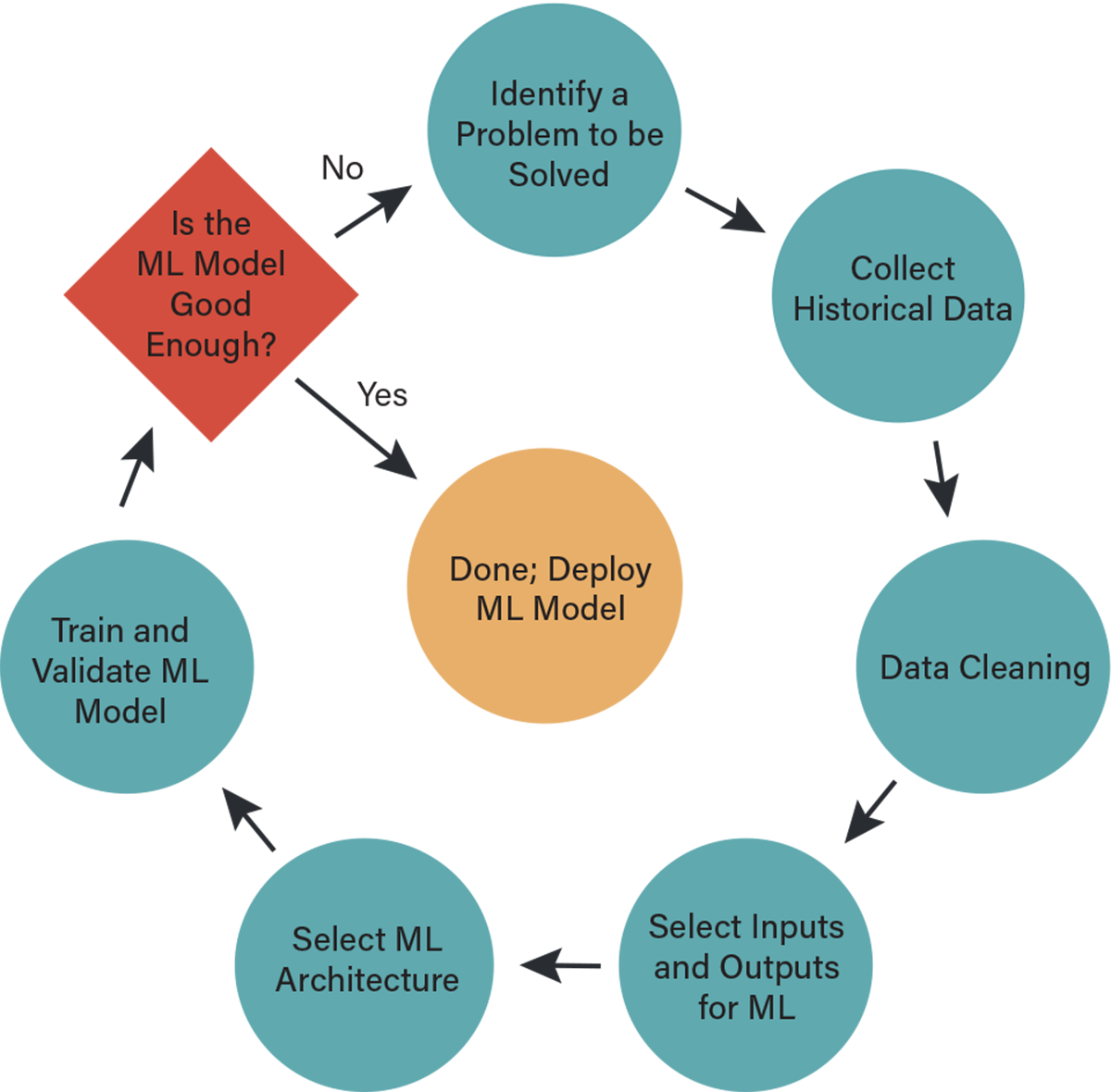
1. Identify a challenging problem related to process design, operation, control, or monitoring, and define the metric(s) that can be used to measure success. For example, if we are interested in making a new type of product, we may want to increase its yield while reducing energy requirements and potential environmental harm.
2. Collect historical and/or real-time data for the process. Such data could come from old archives, high-fidelity simulations, or production, to name a few. One obvious challenge involves dealing with multi-modal data that includes two or more of the following: image, text, audio, and/or time-series data in addition to other numerical data sources.
3. Clean the data using statistical means, then verify whether the amount of data is large enough to develop the specific choice of ML model. This can be very tricky since determining the appropriate amount of data is usually done through trial and error. Luckily, statistical strategies such as cross validation can help. It is also recommended that one try several types of ML models and selects the simplest model (least complexity) that achieves high performance, following the concept of prefering the simplest explanation, as suggested by Occam’s razor.
4. Given an input, the ML model is used to predict an output value. A key modeling task is to select the choice of inputs and outputs, which is not always straightforward. In certain cases, the outputs are measured or labeled such that they can be used to teach the model how it should behave. This is called supervised learning.
Classification and regression are the two main supervised learning tasks. Classification maps the inputs to a discrete (categorical) output that has a predefined number of classes, such as normal or abnormal plant operations, while regression maps the inputs to a continuous output such as product yield.
In contrast, unsupervised learning refers to ML models that only learn from input data and thus look to uncover hidden structures within the inputs. The two main unsupervised learning tasks are clustering — grouping similar data together, such as relationships between large sets of spectroscopic data — and dimensionality reduction to compress input data into key signatures.
5. Choosing the inputs represents the first round of features and is critical to training the ML. It is essential that the input features capture the important characteristics of the process, or the modeling task is likely to fail. Unfortunately, the optimal features for modeling are often not known before training takes place, and they can strongly depend on both the type of task (supervised vs. unsupervised) and the model architecture (simple vs. complex). More advanced model architectures (such as convolutional neural networks) can internally “learn” new features, which makes them less susceptible to poor choices of initial inputs. However, as usual, there is no free lunch, and this added complexity comes at the cost of a more difficult training process, which often requires larger amounts of data to complete successfully.
6. Pick an ML architecture that sits between the inputs and the outputs, and then train the ML model. The training process refers to how the parameters and possibly hyperparameters of a model architecture are updated to better reflect the relationship between the inputs and outputs. Much traditional ML modeling relied on notions closely related to the well-known least-squares regression paradigm, which works well when the inputs are very informative and are not too high-dimensional. Current neural network architectures aim to learn such informative features within the hidden layers of the network. Thus, their expressiveness enables them to work more easily “out of the box” on complex data types such as text and images.
7. After training and validation, the model should be tested on a completely new set of data, often referred to as a held-out test set; a passing score means the model is ready to use to make real-time predictions that can be used for decision-making purposes. For example, if the predicted yield in a reactor is too low, then an operator may choose to halt the process and identify the issue, which can be fixed before resuming operation. An important consideration is the range of inputs that are fed to the model; one should only trust the model prediction within a certain operating region that should be identified during the validation phase.
8. If the ML model is “good enough,” it can be deployed for predictions. Otherwise, another cycle of modeling is required. Figure 1 shows “Identify a Problem to be Solved” as the re-entry point, but the modeler can choose other re-entry points depending on factors such as intuition and familiarity with the problem at hand. Metrics for “good enough” have been discussed in the literature but will not be covered here.
Using LLMs in broad ways
The process engineer will use LLMs as increasingly sophisticated engineering assistants, providing digested information for data analysis and prediction, process optimization, and simulation and modeling, where executing such predictions will still need the go-ahead from the appropriate hierarchy of approvers. LLMs can pore through large amounts of data and generate the kind of interpretations needed for process efficiency and safety. One can envision LLMs as supervisory controllers, making autonomous suggestions on optimal process conditions given the plant layout. LLMs are likely to be used to automate the process of documentation, leading to frequent updates of safety reports and standard operating procedures.
Other expected applications are in education and training. Imagine LLMs providing explanations of complex concepts, enabling interactive learning experiences, and simulating laboratory experiments. The possibilities are endless.
In summary, AI/ML and LLMs can help within the chemical engineering enterprise and are evolving rapidly. The challenges are to incorporate them and to envision their uses.
This article is also featured in the ChE in Context column of the July 2024 issue of CEP. Members have access online to complete issues, including a vast, searchable archive of back-issues found at www.aiche.org/cep.